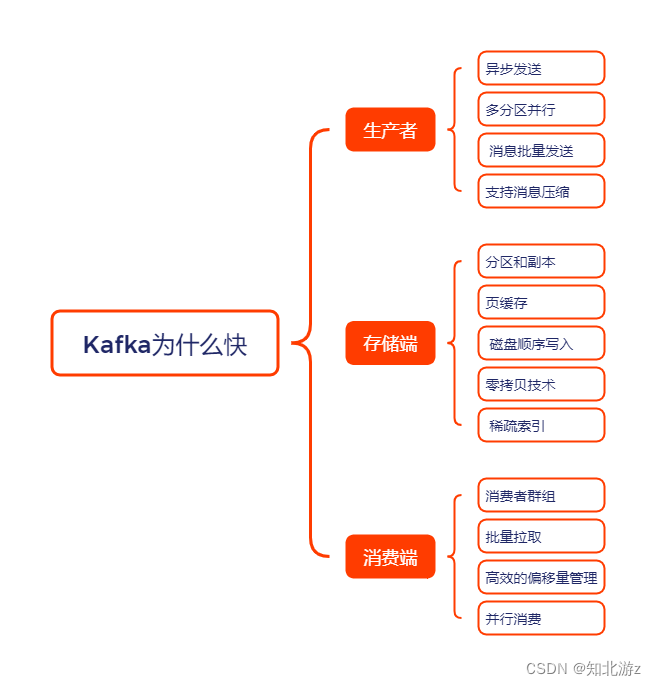
目录
前言
一、生产者
1. 异步发送
2. 多分区并行
3. 消息批量发送
4.支持消息压缩
二、存储端
1. 分区和副本
2. 页缓存
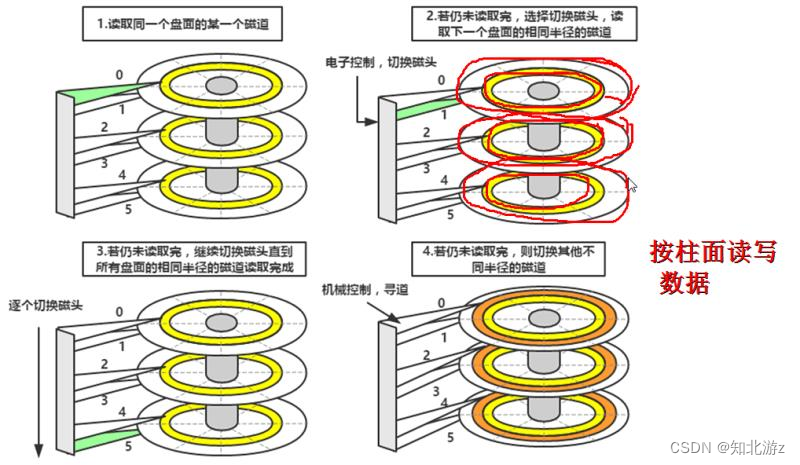
3. 磁盘顺序写入
4. 零拷贝技术
5. 稀疏索引
三、消费端
1. 消费者群组
2. 批量拉取
3. 高效的偏移量管理
4. 并行消费
总结
前言
Kafka 作为一款分布式消息系统,需应对海量消息的处理工作。Kafka 的设计思路是将所有消息全部写入速度较低但容量巨大的硬盘,借此获取更强大的存储能力,同时使用硬盘这种方式并未造成过多的性能损耗。Kafka单个节点的极限可以处理能力接近每秒 2000万 条消息,是一个相当出色的实时消息流处理平台。本篇文章将带你了解Kafka 通过哪些方式实现这么高的吞吐量。
一、生产者
1. 异步发送
在发送消息时,Kafka 支持异步发送。这意味着应用程序可以将消息放入发送缓冲区后立即返回,而无需等待消息被确认发送成功。这种方式极大地提高了发送消息的效率,减少了应用程序的阻塞时间。例如,在一个高并发的电商系统中,用户的下单操作可以快速将订单信息异步发送到 Kafka,而不会影响用户的下单体验。
2. 多分区并行
Kafka 中的分区(Partition)概念是实现高吞吐量的重要基石。生产者通过创建多个分区,将数据分散到不同的存储和处理单元。这就好比将一个大型任务分解为多个子任务,由多个团队并行处理。每个分区都可以独立地接收和存储消息,从而实现了并行写入,大大提升了整体的写入速度。 例如,假设有一个电商平台,每秒产生大量的订单消息。通过将订单消息按照不同的地区或商品类别分配到不同的分区,可以让不同的服务器同时处理这些分区的消息,而不是让单个服务器处理所有的订单,从而显著提高了处理速度。
3. 消息批量发送
Kafka生产者在消息发送之前,会先把消息存储在 RecordBatch 中。当 RecordBatch 中的消息达到一定数量或者经过一定时间后,再统一进行发送。 这种批量处理的方式有效地减少了网络请求和系统调用的次数。想象一下,每次发送一条消息就像单独邮寄一个小包裹,而批量发送则像是将多个小包裹打包成一个大包裹一起邮寄。这样不仅减少了邮寄的次数,还降低了每次邮寄的准备工作和相关费用。 在实际应用中,比如一个监控系统每秒产生大量的性能指标数据,如果每条数据都单独发送,将会产生巨大的网络开销和系统资源消耗。而通过批量发送,能够显著降低这些成本,提高数据生产的效率。
4.支持消息压缩
Kafka 支持在发送端进行数据压缩,启用消息压缩后,可以有效地提升数据传输效率,减少数据量,降低网络带宽的占用。 然而,压缩和解压过程会增加 CPU 的计算量。因此,在选择是否压缩以及采用何种压缩算法时,需要综合考虑数据的特点、网络带宽和 CPU 资源等因素。 例如,如果数据本身具有较高的重复性或可压缩性,如文本日志数据,使用压缩可以在不显著增加 CPU 负担的情况下,大幅减少网络传输的数据量。但对于已经高度压缩或计算密集型的数据,压缩可能带来的收益就相对较小,甚至可能因为增加的 CPU 计算量而影响整体性能。
Kafka 默认情况下消息不进行压缩,生产者(Producer)在发送消息时,可以通过配置参数compression.type来指定消息的压缩类型。
二、存储端
1. 分区和副本
通过分区,数据可以分布在不同的节点上进行存储和处理,实现了并行和负载均衡。副本机制则保证了数据的可靠性和可用性。比如,在一个分布式的金融交易系统中,交易数据通过分区存储,同时副本保证了数据不会因为节点故障而丢失。
2. 页缓存
数据先存在 PageCache 中,定时 flush 到硬盘上。PageCache 是操作系统用于缓存磁盘数据的内存区域,其读写速度远高于磁盘。 当生产者写入数据时,首先将数据写入 PageCache。由于内存的高速读写特性,这一过程非常迅速。然后,Kafka 会定时将 PageCache 中的数据 flush 到硬盘上,确保数据的持久化存储。 这种方式充分利用了内存的优势,减少了直接对硬盘的频繁写入操作。在实际场景中,比如一个实时的金融交易系统,短时间内会产生大量的交易数据,通过将这些数据先缓存在 PageCache 中,可以快速响应生产者的写入请求,保证系统的低延迟和高吞吐量。
3. 磁盘顺序写入
Kafka 采用顺序写磁盘的方式,这是其实现快速写入的原因之一。相比于随机写磁盘,顺序写磁盘的速度要快得多。 当写入数据时,Kafka 将消息依次追加到文件的末尾,就像在一个长长的卷轴上连续书写,而不是在不同的位置随机跳跃着书写。这种顺序写的方式避免了磁盘磁头的频繁寻道和旋转等待,大大提高了写入的效率。 以一个视频流媒体平台为例,大量的视频播放记录需要快速存储。采用 Kafka 的顺序写方式,可以高效地将这些记录连续写入磁盘,确保系统能够及时处理海量的用户行为数据。
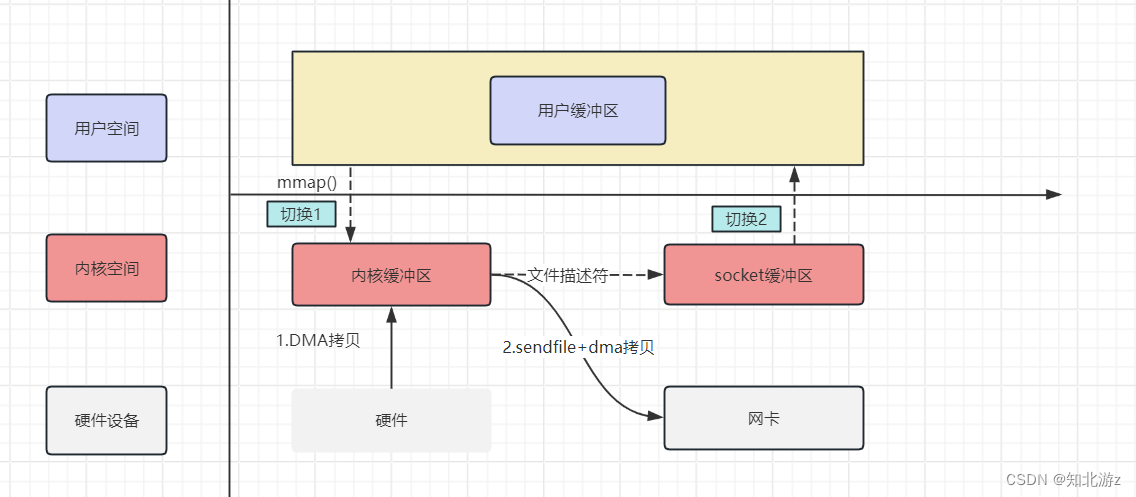
4. 零拷贝技术
消费者利用零拷贝技术从 socket 缓冲区中读取数据,避免了不必要的数据拷贝,极大地提高了数据读取的效率。
传统的数据读取方式通常需要多次数据拷贝,从磁盘到内核缓冲区,再从内核缓冲区到用户空间缓冲区。而Kafka 利用了 Linux 的 sendFile 技术(NIO)零拷贝技术,省去了进程切换和一次数据拷贝。
5. 稀疏索引
Kafka的索引并不是每一条消息都会建立索引,而是一种稀疏索引 也就是说,Kafka插入一批消息才会产生一条索引记录。后续利用二分查找,可以大大提高检索效率。 稀疏索引:kafka存储消息是通过分段的日志文件,每个分段都有自己的索引文件,这些索引文件中的条目不 是对分段中的每条消息都建立索引,而是每隔一定数量的消息建立一个索引点,这就构成了稀疏索引,稀疏索 引减少了索引大小,使得加载到内存中的索引更小,提高了查找特定消息的效率。例如,在一个大规模的日志存储系统中,稀疏索引可以帮助快速找到特定时间段的日志。
三、消费端
1. 消费者群组
Kafka 引入了消费者组(Consumer Group)的概念,多个消费者可以组成一个消费者组共同消费数据。通过消费者组的机制,可以实现负载均衡,提高数据消费的效率。 当组内的某个消费者出现故障时,其他消费者可以自动接管其未消费的分区,确保数据不会丢失和积压。这种自动的故障转移和负载均衡机制,使得 Kafka 在数据消费方面具有高度的可靠性和扩展性。 比如在一个分布式计算系统中,多个计算节点组成消费者组来消费任务分配消息,通过消费者组的协调工作,可以保证任务的均衡分配和高效处理。
2. 批量拉取
消费者不是逐个获取消息,而是批量拉取消息进行处理。这样减少了网络请求次数,提高了消费的性能。比如,在一个数据处理任务中,一次性拉取一批数据进行处理,而不是频繁地拉取单个数据。
3. 高效的偏移量管理
Kafka 为消费者提供了偏移量(Offset)的概念,用于记录消费者消费的位置。通过高效的偏移量管理,消费者可以准确地从上次停止的位置继续消费,避免了重复消费或数据丢失。 偏移量的存储和管理方式也经过了精心设计,以确保其高效性和可靠性。例如,可以将偏移量存储在专门的主题中,或者使用外部存储系统来保证其持久性。 在一个实时数据分析系统中,准确的偏移量管理能够确保数据分析的连续性和完整性,提高数据处理的效率和准确性。
4. 并行消费
消费者可以同时处理多个分区的消息,提高消费的效率。例如,在一个数据分析系统中,可以同时对多个数据源的消息进行分析处理。
总结
综上所述,Kafka 在发送端、存储端和消费端的一系列优化策略,使得它能够在大数据处理场景中展现出惊人的速度和性能。无论是构建实时数据管道、流处理应用还是大规模的消息系统,Kafka 都是一个可靠且高效的选择。 希望通过这篇文章,能让您对 Kafka 为什么快有更深入的理解。
本文内容的思维导图如下: